SALT Galata'da bir "Arşiv Rüyası"
15 Mart 2017

SALT Araştırma ve Programlar Direktörü Vasıf Kortun, 20 Nisan’da SALT Galata’da açılacak olan Arşiv Rüyası’nın oluşumu ve hazırlık süreçleri üzerine sanatçı Refik Anadol ile söyleşti.
SALT Araştırma koleksiyonlarından izleyiciyi saran bir arayüz oluşturarak müze ve koleksiyon kavramlarına meydan okuyan, kullanıcı güdümünde bir sanal gerçeklik deneyimi tasarlayan Anadol’un projesi, SALT Galata -1 katındaki sergi mekânını gelecek ve geçmişin içe içe geçtiği, kapsayıcı bir ortama dönüştürecek.
- - -
Vasıf Kortun: t-SNE kısaltmasıyla ifade edilen ve Türkçe’ye “t-dağıtık [stokastik] olasılıklı yakınlık gömmesi” şeklinde çevrilebilecek olan t-distributed stochastic neighbor embedding‘den biraz bahsedebilir misin? 2008’de geliştirilen bir algoritma olduğunu, makine öğrenmesinde kullanıldığını ve çok boyutlu verilerin görselleştirilmesinde yeni bir dönem başlattığını biliyoruz. Çok boyutlu dediğimizde yüzlerce, binlerce boyuttan söz edebiliyoruz ve bunlar çizgisel de değil; t-SNE algoritması veriye uyum gösteriyor. Bunu benim gibi, bu işlerden pek anlamayan birine anlatabilir misin? Bu algoritmaların boyu nedir? Veri dediğimiz zaman kendi başına duran bir şeyden söz etmiyorsak veriye nasıl müdahale ediliyor?
Refik Anadol: Google Artists and Machine Intelligence [Google Sanatçılar ve Makine Zekâsı] ekibiyle projeyi tartışmaya başladığımız Eylül 2016’daki ilk toplantıda çok önemli bir an oldu: Beyaz bir dijital tahta ve birçok kısaltmadan oluşan 12 tane algoritmaya dair bir çizelge, bize her bir algoritmayı tek tek inceleyerek hangisinin makine öğrenmesinde, ne için kullanıldığını özetliyordu. Bunlar arasında t-SNE’nin hiç şüphesiz belirli bir ayrışması söz konusuydu. Bu algoritma, tıpkı bir masanın üstünde dağınık duran birbirinden farklı onlarca nesneyi ayıklayıp benzerliklerine göre yeniden şekillendiriyormuşçasına veriye mekân ve zaman algısı tanımlayabiliyordu.
SALT Araştırma arşivleri, hâlihazırda hem meta veri sayesinde hem de okunabilir seviyede şahane bir varlığa sahip ve aynı zamanda, “Bu varlık makine için tam olarak nedir?”, “Dijital gerçeklikte nasıl bir mekândır?”, “Bu milyonlarca veri arasındaki ilişkiyi bir bakışta görebilir miyiz?” gibi sorulara cevap verebilmenin de önünü açabiliyor. Bunu yaparken her bir veriyi tek tek 128’e 128 piksellik iki boyutlu bir düzlemde inceleyip sonrasında binlerce boyutlu bir boyuta yayıyor ve son olarak, üç veya iki boyutlu bir mekâna indirgeyip yeniden düzenleyerek bize sunabiliyor, en önemlisi de okunabilir bir hâle getirebiliyor. Bu hesaplamaların yapıldığı mekâna Latent Space [Örtük Uzay] deniyor. Bu tanımı öğrendiğimde, çalışmalarımda görülemeyeni görülür kılabilen her yaklaşım gibi, bu da aklımı başımdan aldı. Aslında veri, yapay zekâ tarafından anlamlandırılmaya çalışıldığında kendine bir mekân yaratabiliyordu. Bu sergide de, yapay zekânın veriyi anlamlandırma sırasında başına gelenlere “şiirsel” bir şekilde mercek tutuyoruz. Ortaya çıkan örtük uzayları görselleştiriyor, izleyiciye içerisinde yolculuk etme fırsatı veriyoruz. Bir anlamda belki de ilk defa, yapay zekânın bıraktığı izler, nöronları ve kurabildiği ilişkiler arasında insan olarak yer alabiliyoruz. Bu zahirî gerçekliğe dair mekân kurma çabası, bize yepyeni okuma ve görme biçimleri sunuyor.
Verinin kendisinden çok okuma/görme biçimine müdahale ettiğimiz üç nokta mevcut: İlki ve en önemlisi özveriyle hazırlanmış, kültürel anlamı kabul görmüş bu veri bankasını makinenin okuma şeklinin tanımlanması (A’dan Z’ye mi, imajdan metne mi, yoksa resimden fotoğrafa mı vb.); ikinci müdahale, hangi imaj tanıma ağının kullanılacağına karar verilmesi (ImageNET gibi dünyanın tek açık kaynaklı 10 milyon+ imajlık yapay zekâ öğretme veri ağı) ve son olarak da perplexity [çapraşıklık], yani bunu yaparken algoritmanın ne seviyede bir bulanıklık veya keskinlikle karar vermesini istiyor olmamız. Bu süreçte özellikle en bulanık ve en keskin kontrast sonuçları da inceleme imkânı bulduk.
Temel fikir, belgeleri kavramsal görünümlerine göre düzenlemek. Bunun için, her görüntü öncelikle genel amaçlı bir görüntü tanıma ağı içerisinden geçiriliyor. Bunu nihai bir sınıflandırma için kullanmıyoruz. Sinirsel ağın sonuç olarak bulduğu mutlak sınıflandırma verisi yerine, çağrışım sırasında aktive olan sinirsel ağa dair birkaç algılayıcının (perceptron1) ortalama değerini temel alıyoruz. Böylece ön yargılı bir sınıflandırmanın önüne geçilebiliyor.
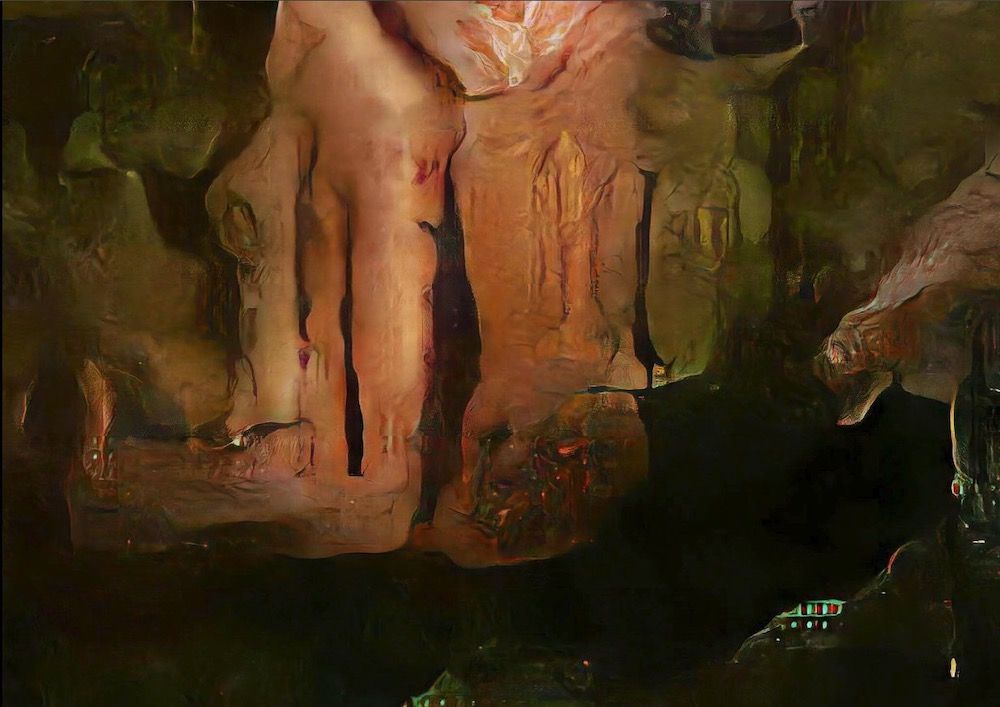
V.K.: SALT Araştırma’da kataloglama esnasında her belge için ayrı giriş yapıyoruz. Özelliği, tarihi, yeri, üreteni, materyali gibi, her belgeye dair 30-40 civarında bilgi hücresi ve bir de bunların üzerine eklenen anahtar kelimeler var. Farklı farklı uzmanlık alanlarına ve çeşitli yabancı dil bilgisine başvuruyoruz. Bunlar erişimi kolaylaştırmak için gerekli. Her ne kadar özen gösterilse de, araştırmacıların da kataloglamayı yapan insanlar kadar bilgili olmaları bir ön kabul gibi. t-SNE’nin bu anlamda arşivciliğe bir katkısı olabilir mi, yani sivilleştirebilir mi? Yoksa özünde merak geliştirmede mi yardımcı olur? Arşivcilere nasıl bir araç sunar?
R.A.: t-SNE ve diğer muhtemel makine öğrenme algoritmalarının arşivciliğe muazzam derecede olumlu katkısı olacağını düşünüyorum. Sırf bu araştırma sürecinde dahi bu kadar devasa bir arşivin kolaylıkla tek bir büyük resim içerisinde görünür kılınabileceği ortaya konuyor. Birbirinden tamamen bağımsız her bir veri noktasının diğer benzer veri noktalarıyla arasındaki ağı görülebilir hâle getiriyor; yüzbinlerce verinin analizi sonucuna, ihtimalini tahmin bile edemediğimiz kompleks araştırma metotlarına dair yepyeni bir şey söyleyebiliyoruz. Sivilleştirilmesi için en büyük çabanın GitHUB gibi açık kaynaklı kodların anlaşılır seviyede paylaşılmasıyla başladığına inanıyorum. Bu süreçte Google destekçimiz olsa da, kullandığımız tüm algoritmalar tamamen açık kaynaklı. Bunun verdiği özgürlük ve bağımsız düşünebilme rahatlığıyla sınırsız bir yaratıcı söyleme ve dolayısıyla hem sanat hem de tasarım anlamında yepyeni buluş ve keşiflere doğru rüzgârı kesintisiz, sonsuz bir yelkenli yolculuğuna dönüşüyor.
V.K.: Çapraşıklık konusu, yanılmıyorsam olasılıklı yakınlıkların ölçülmesi anlamına geliyor. Düşük ve yüksek çapraşıklık arasındaki farkı, bu arşiv bağlamında biraz anlatır mısın? Bu işte nasıl bir çapraşıklığa karar verdin? İşin püf noktası da aslen bu sayılır, değil mi? SALT Araştırma arşivlerindeki iki milyona yakın belgeden söz ettiğimizde ne değişiyor?
R.A.: Çapraşıklık, kesinlikle işin püf noktası ve bu kompleks algoritmanın en keyifli, en insani kelimesi; yapay sinir ağlarında bize dair izler bırakmamızı sağlayabilen tek değişken. Aslında tüm süreç, bir grup noise [parazit] içeren partikülle başlıyor; adım adım bu parazit, veriyi tek tek okuyup anlayarak anlam ve şekil kazandırıyor. Bu, insanın öğrenme sürecine tıpatıp benzeyen bir serüven. Dolayısıyla çapraşıklığı, araştırmalarımızda ne kadar derine inmemiz gerektiğine karar veren içgüdüsel bilincimiz ile bir sonuca vardığımıza inanmanın yeter şartları arasındaki ilham verici çarpışma olarak tanımlayabiliriz.
V.K.: t-SNE’nin bu kadar esnek olması, arşivin görselleştirilmesi ve okunmasında bir sorun mu? Göremediğimiz bir algoritma kendine göre görselleştirmeler yapıyor, ki buna yaptığı düzeltmeler de dâhil. Biz arşivde kataloglama yaparken ne kadar öznel kararlar verebileceğimizin farkındayız, ideolojiler de o kadar muğlak değil. Peki, makine öğrenmesinde öznellik nasıl tarif edilir? Düzeltme neye göre yapılır? Uyumlama sürecini merak ediyorum yani. Öte yandan, çok ciddi bir “doğruluk” seviyesi olduğunu biliyoruz.
R.A.: Evet, aslında bu bir sorun fakat kolayca çözülebilir bir nitelikte. Laurens van der Maaten, t-SNE hakkında yazdığı makalede bu konuyu şöyle ifade ediyor: “The most appropriate value depends on the density of your data” [En uygun değer, verilerinizin yoğunluğuna bağlıdır]. Yani, ne kadar öğrenebilir ve olasıkları artırabilirsek o kadar non-linear [çizgisel olmayan] ve dolayısıyla non-convex [dışbükey olmayan] bir gerçeklik simüle edebiliyoruz. Bu da bize 05-50 arası gibi 5’er 5’er artan bir bulanıklık ölçeklendirmesi sağlıyor. Arşiv, en bulanık zihinle sadece iki milyona yakın noktadan oluşan yalın bir küreye dönüşüyor; yapay sinir ağlarını çalıştırdığımızda, 25 parametresi ile tam bir küreye dönüşemeyen dağınık bir karar mekânizmasına sahip olduğunu görüyoruz. 50 parametresi ile çalıştırdığımızdaysa, yüzlerce organik gruptan oluşan, muhteşem uyumlu bir heykel niteliğinde bir sonuç ortaya çıkarıyor. Bu sonuç, algoritmanın kendisine verilen birim zaman ile bilişim [data processing] gücüne verdiği en keskin yanıt oldu.

V.K.: Genelde deep dream [derin düş], inceptionism [başlangıçcılık] çok ilginç görüntüler vermiyor. Neden buna başlangıçcılık gibi batınî bir isim verilmiş? Bana geçen hafta Osmanlı Bankası Arşivleri’nden yolladığın iki derin düş görüntüsüyse çok farklı ve yorumlamaya açıktı. Sen bununla ilgilenmeye ne zaman başladın?
R.A.: Google ekibinin 2015 yılı sonunda paylaştığı açık kaynaklı kod sonrasında konuyla ilgilenmeye başladım. Benim için en etkileyici nokta, görsel biçimden öte kavramsal olarak yapay sinir ağlarına insani müdahalenin getirebilecekleriydi. Ocak 2016’da Google’ın Sanatçılar ve Makine Zekâsı ekibinin yeni bir program açtığını ve bu programda makine öğrenmesine ihtiyaç duyulan sanatsal fikirlere sahip kişi ve kurumlara öğretici destek verileceğini öğrendim. Bu kapsamda düzenlenen ilk panelde sanatçı olarak konuşmacı oldum ve orada Google’ın yapay zekâ mühendisleri Mike Tyka ve Kenric McDowell ile SALT projemizi sözlü paylaştım. Ve sonrasında bu alana dair bilgimi pekiştirmeye, yorumunuza katılarak çok ilginç olmayan bu yapay zekâ çıktısı görüntülerini ve onlara dair yöntemleri tekrar yorumlamaya karar verdim. Hâlen medya sanatçısı seviyesinde üretim biçimlerini öğrenmeye devam ediyorum.
Size gönderdiğim ilk denemeler, algoritmanın hata payının en yüksek değerlerine karşılık gelen varsanılarıydı. Bu sırada birkaç yeni fikir daha oluştu: Mike Tyka2 ile arşivin kendi meta veri formatını koruyarak yeni bir halüsinasyon görme biçimi oluşturabilir mi diye düşünmeye başladık. Mesela bu konuşma sırasında bizlere ilham veren şeyin, hem projenin bağlamı hem de bağlamı ortaya çıkaran algoritmaların kendisi olduğunu fark ettik. Tam anlamıyla Google ekibinin ismini verdiği araştırma grubunu haklı çıkarır bir durum; Sanatçılar ve Makine Zekâsı. Algoritmalarla düşünebiliyor olmak ve yapay zekâ ağlarına dair ortaya çıkan eşleştirme sonuçlarına bakıp ilham alabilmek… Bunun, projenin zahmetli fakat bir o kadar da biricik özelliklerinden biri olduğunu düşünüyorum. Acaba bu metotları kullanarak yeni arşiv belgeleri oluşturabilir miyiz? Arşiv, kendi içerisindeki ağların bağlarına dair ilişkileri bir belgeye dönüştürebilir mi? İzleyiciyi çevreleyen, interaktif ve mimari zekâya [architectural intelligence] sahip sergi mekânının en yenilikçi söyleminin, sunacağı halüsinasyonlar olacağını düşünüyorum. Hem alternatif bir gerçeklik hem de kültüre dair bir rüya makinesine doğru giden bir çalışmanın henüz başındayız gibi hissediyorum.
Yapay sinir ağları, bir dizi imgenin iç bağlılıklarını öğrenmek için de kullanılabilir. Bu, imgelerdeki piksellerin birbirlerine göre nasıl davrandıklarının kurallarını, yani imgeleri yöneten kuralları öğrenmek anlamına geliyor. Burada kullandığımız yöntem, iki ağ arasında bir zıtlık oyunu kurmak. Gerçek belgeleri sahte belgelerden ayırmayı öğrenmeye çalışan bir ayırt edici ağ ve ayırt ediciye aykırı görünen sahte içerikler üretmeye çalışan bir üreteç. Üreteç eğitildiği zaman, aynı istatistik kurallarına dayanan yeni görüntüler üretmek için kullanılabililir ve hiç var olmamış ama gerçek belgelere benzeyen belgeler yaratabilir; kim bilir tarihin başka bir sürümünden gelebilecek belgeler gibi…
V.K.: Bu harika bir fikir! Bildiğimiz dünya içinde hiç var olmamış ama gerçek belgelere benzeyen belgeler… Bu, aslında bir başka tarih anlatısı değil, bir paralel dünya; var olanın içine katlanan başka olası dünyalar gibi.
Blaise Agüera y Arcas’ın Sanatçılar ve Makine Zekâsı ile derin düş hakkında yaptığı, benimle de paylaştığın konuşmayı izledim. Tüm mekanizma, percept3‘ten concept‘e çeviri üzerine ve bu çok değerli bir araç. Araştırmalarımızı muazzam derecede kolaylaştırıyor; tanımlama, kataloglama ve ilişkilendirme süreçlerine katkısı olağanüstü. Bir fotoğrafın hangi tarihte çekildiğini anlayabilmek bugün çok daha kolay, içerdiği tüm ögeleri envanterlemek de öyle. Sinir ağına yerleşmesinden ötürü çizgisel sıralamayla da bağları kopuyor.
Bugüne kadar alışmadığımız bir “sanatçı” nosyonu mu söz konusu? Sanatçıların kullandıkları aygıtlarla çok derin ilişkileri olur ama burada aygıtla bir arayüz ilişkisi mi var? Eşiğinde olduğumuz dünya, biricikliğin nesneler üzerinden tarif edilmesine izin vermediği gibi, aygıtın değişken bir zekâsı da mevcut.
R.A.: Çok teşekkürler. Bu projeyi, beraber çıktığımız bir yolculuk olarak algılıyor ve burada daha nice ilham verici ve sürpriz dolu karşılaşmanın olacağına inanıyorum. Kamusal alanda bu denli kompleks, bilişim ve teknoloji odaklı fikir ve tasarılara dair sanat üretimi, kesinlikle alışmadığımız bir “sanatçı” nosyonu oluşturuyor. Size katılarak ve ekleyerek; “sanat” kavramı, makine zekâsıyla kavramsal bir interaktif iletişim kurabildiğimizde yepyeni bir boyut algısı ve dolayısıyla yepyeni bir zaman/mekân kavramı sonucu tamamen değişecektir diye düşünüyorum. Ayrıca, bugüne kadar sanatsal olarak en çok etkilendiğim ışık ve mekân hareketinin -belki de zamanımıza uygun bir şekilde- aygıtla olan ilişkilerimize göre tekrardan can bulabildiğini de görebilmek beni çok heyecanlandırıyor. Mesela, bu projede örtük uzay gibi bir mekânı, tasarladığımız arayüz ile görülebilir kılabiliyor ve oluşumuna tanıklık ediyor olacağız. Bu kendine ait zaman ve mekân kavramı içerisinde, çizgisel olmayan bir zaman ve biricik olmayı ümit eden çok sayıda verinin arasında bir yolculuğa çıkabileceğiz. Bazen bu sohbetimizi bilim-kurgu romanından fırlamış bir kesit gibi düşünüyorum. Biraz zaman geçiyor, bilgisayarımdaki açık pencerelere bakıyor ve aslında gerçek olduğunu görüyorum. İşte bu ve bunun gibi düşünce ve üretim biçimi, yaklaşan devrimin sadece küçük bir izi…
SALT Araştırma koleksiyonlarından izleyiciyi saran bir arayüz oluşturarak müze ve koleksiyon kavramlarına meydan okuyan, kullanıcı güdümünde bir sanal gerçeklik deneyimi tasarlayan Anadol’un projesi, SALT Galata -1 katındaki sergi mekânını gelecek ve geçmişin içe içe geçtiği, kapsayıcı bir ortama dönüştürecek.
Vasıf Kortun: t-SNE kısaltmasıyla ifade edilen ve Türkçe’ye “t-dağıtık [stokastik] olasılıklı yakınlık gömmesi” şeklinde çevrilebilecek olan t-distributed stochastic neighbor embedding‘den biraz bahsedebilir misin? 2008’de geliştirilen bir algoritma olduğunu, makine öğrenmesinde kullanıldığını ve çok boyutlu verilerin görselleştirilmesinde yeni bir dönem başlattığını biliyoruz. Çok boyutlu dediğimizde yüzlerce, binlerce boyuttan söz edebiliyoruz ve bunlar çizgisel de değil; t-SNE algoritması veriye uyum gösteriyor. Bunu benim gibi, bu işlerden pek anlamayan birine anlatabilir misin? Bu algoritmaların boyu nedir? Veri dediğimiz zaman kendi başına duran bir şeyden söz etmiyorsak veriye nasıl müdahale ediliyor?
Refik Anadol: Google Artists and Machine Intelligence [Google Sanatçılar ve Makine Zekâsı] ekibiyle projeyi tartışmaya başladığımız Eylül 2016’daki ilk toplantıda çok önemli bir an oldu: Beyaz bir dijital tahta ve birçok kısaltmadan oluşan 12 tane algoritmaya dair bir çizelge, bize her bir algoritmayı tek tek inceleyerek hangisinin makine öğrenmesinde, ne için kullanıldığını özetliyordu. Bunlar arasında t-SNE’nin hiç şüphesiz belirli bir ayrışması söz konusuydu. Bu algoritma, tıpkı bir masanın üstünde dağınık duran birbirinden farklı onlarca nesneyi ayıklayıp benzerliklerine göre yeniden şekillendiriyormuşçasına veriye mekân ve zaman algısı tanımlayabiliyordu.
SALT Araştırma arşivleri, hâlihazırda hem meta veri sayesinde hem de okunabilir seviyede şahane bir varlığa sahip ve aynı zamanda, “Bu varlık makine için tam olarak nedir?”, “Dijital gerçeklikte nasıl bir mekândır?”, “Bu milyonlarca veri arasındaki ilişkiyi bir bakışta görebilir miyiz?” gibi sorulara cevap verebilmenin de önünü açabiliyor. Bunu yaparken her bir veriyi tek tek 128’e 128 piksellik iki boyutlu bir düzlemde inceleyip sonrasında binlerce boyutlu bir boyuta yayıyor ve son olarak, üç veya iki boyutlu bir mekâna indirgeyip yeniden düzenleyerek bize sunabiliyor, en önemlisi de okunabilir bir hâle getirebiliyor. Bu hesaplamaların yapıldığı mekâna Latent Space [Örtük Uzay] deniyor. Bu tanımı öğrendiğimde, çalışmalarımda görülemeyeni görülür kılabilen her yaklaşım gibi, bu da aklımı başımdan aldı. Aslında veri, yapay zekâ tarafından anlamlandırılmaya çalışıldığında kendine bir mekân yaratabiliyordu. Bu sergide de, yapay zekânın veriyi anlamlandırma sırasında başına gelenlere “şiirsel” bir şekilde mercek tutuyoruz. Ortaya çıkan örtük uzayları görselleştiriyor, izleyiciye içerisinde yolculuk etme fırsatı veriyoruz. Bir anlamda belki de ilk defa, yapay zekânın bıraktığı izler, nöronları ve kurabildiği ilişkiler arasında insan olarak yer alabiliyoruz. Bu zahirî gerçekliğe dair mekân kurma çabası, bize yepyeni okuma ve görme biçimleri sunuyor.
Verinin kendisinden çok okuma/görme biçimine müdahale ettiğimiz üç nokta mevcut: İlki ve en önemlisi özveriyle hazırlanmış, kültürel anlamı kabul görmüş bu veri bankasını makinenin okuma şeklinin tanımlanması (A’dan Z’ye mi, imajdan metne mi, yoksa resimden fotoğrafa mı vb.); ikinci müdahale, hangi imaj tanıma ağının kullanılacağına karar verilmesi (ImageNET gibi dünyanın tek açık kaynaklı 10 milyon+ imajlık yapay zekâ öğretme veri ağı) ve son olarak da perplexity [çapraşıklık], yani bunu yaparken algoritmanın ne seviyede bir bulanıklık veya keskinlikle karar vermesini istiyor olmamız. Bu süreçte özellikle en bulanık ve en keskin kontrast sonuçları da inceleme imkânı bulduk.
Temel fikir, belgeleri kavramsal görünümlerine göre düzenlemek. Bunun için, her görüntü öncelikle genel amaçlı bir görüntü tanıma ağı içerisinden geçiriliyor. Bunu nihai bir sınıflandırma için kullanmıyoruz. Sinirsel ağın sonuç olarak bulduğu mutlak sınıflandırma verisi yerine, çağrışım sırasında aktive olan sinirsel ağa dair birkaç algılayıcının (perceptron1) ortalama değerini temel alıyoruz. Böylece ön yargılı bir sınıflandırmanın önüne geçilebiliyor.
Arşiv Rüyası, 13 Şubat 2017
V.K.: SALT Araştırma’da kataloglama esnasında her belge için ayrı giriş yapıyoruz. Özelliği, tarihi, yeri, üreteni, materyali gibi, her belgeye dair 30-40 civarında bilgi hücresi ve bir de bunların üzerine eklenen anahtar kelimeler var. Farklı farklı uzmanlık alanlarına ve çeşitli yabancı dil bilgisine başvuruyoruz. Bunlar erişimi kolaylaştırmak için gerekli. Her ne kadar özen gösterilse de, araştırmacıların da kataloglamayı yapan insanlar kadar bilgili olmaları bir ön kabul gibi. t-SNE’nin bu anlamda arşivciliğe bir katkısı olabilir mi, yani sivilleştirebilir mi? Yoksa özünde merak geliştirmede mi yardımcı olur? Arşivcilere nasıl bir araç sunar?
R.A.: t-SNE ve diğer muhtemel makine öğrenme algoritmalarının arşivciliğe muazzam derecede olumlu katkısı olacağını düşünüyorum. Sırf bu araştırma sürecinde dahi bu kadar devasa bir arşivin kolaylıkla tek bir büyük resim içerisinde görünür kılınabileceği ortaya konuyor. Birbirinden tamamen bağımsız her bir veri noktasının diğer benzer veri noktalarıyla arasındaki ağı görülebilir hâle getiriyor; yüzbinlerce verinin analizi sonucuna, ihtimalini tahmin bile edemediğimiz kompleks araştırma metotlarına dair yepyeni bir şey söyleyebiliyoruz. Sivilleştirilmesi için en büyük çabanın GitHUB gibi açık kaynaklı kodların anlaşılır seviyede paylaşılmasıyla başladığına inanıyorum. Bu süreçte Google destekçimiz olsa da, kullandığımız tüm algoritmalar tamamen açık kaynaklı. Bunun verdiği özgürlük ve bağımsız düşünebilme rahatlığıyla sınırsız bir yaratıcı söyleme ve dolayısıyla hem sanat hem de tasarım anlamında yepyeni buluş ve keşiflere doğru rüzgârı kesintisiz, sonsuz bir yelkenli yolculuğuna dönüşüyor.
V.K.: Çapraşıklık konusu, yanılmıyorsam olasılıklı yakınlıkların ölçülmesi anlamına geliyor. Düşük ve yüksek çapraşıklık arasındaki farkı, bu arşiv bağlamında biraz anlatır mısın? Bu işte nasıl bir çapraşıklığa karar verdin? İşin püf noktası da aslen bu sayılır, değil mi? SALT Araştırma arşivlerindeki iki milyona yakın belgeden söz ettiğimizde ne değişiyor?
R.A.: Çapraşıklık, kesinlikle işin püf noktası ve bu kompleks algoritmanın en keyifli, en insani kelimesi; yapay sinir ağlarında bize dair izler bırakmamızı sağlayabilen tek değişken. Aslında tüm süreç, bir grup noise [parazit] içeren partikülle başlıyor; adım adım bu parazit, veriyi tek tek okuyup anlayarak anlam ve şekil kazandırıyor. Bu, insanın öğrenme sürecine tıpatıp benzeyen bir serüven. Dolayısıyla çapraşıklığı, araştırmalarımızda ne kadar derine inmemiz gerektiğine karar veren içgüdüsel bilincimiz ile bir sonuca vardığımıza inanmanın yeter şartları arasındaki ilham verici çarpışma olarak tanımlayabiliriz.
V.K.: t-SNE’nin bu kadar esnek olması, arşivin görselleştirilmesi ve okunmasında bir sorun mu? Göremediğimiz bir algoritma kendine göre görselleştirmeler yapıyor, ki buna yaptığı düzeltmeler de dâhil. Biz arşivde kataloglama yaparken ne kadar öznel kararlar verebileceğimizin farkındayız, ideolojiler de o kadar muğlak değil. Peki, makine öğrenmesinde öznellik nasıl tarif edilir? Düzeltme neye göre yapılır? Uyumlama sürecini merak ediyorum yani. Öte yandan, çok ciddi bir “doğruluk” seviyesi olduğunu biliyoruz.
R.A.: Evet, aslında bu bir sorun fakat kolayca çözülebilir bir nitelikte. Laurens van der Maaten, t-SNE hakkında yazdığı makalede bu konuyu şöyle ifade ediyor: “The most appropriate value depends on the density of your data” [En uygun değer, verilerinizin yoğunluğuna bağlıdır]. Yani, ne kadar öğrenebilir ve olasıkları artırabilirsek o kadar non-linear [çizgisel olmayan] ve dolayısıyla non-convex [dışbükey olmayan] bir gerçeklik simüle edebiliyoruz. Bu da bize 05-50 arası gibi 5’er 5’er artan bir bulanıklık ölçeklendirmesi sağlıyor. Arşiv, en bulanık zihinle sadece iki milyona yakın noktadan oluşan yalın bir küreye dönüşüyor; yapay sinir ağlarını çalıştırdığımızda, 25 parametresi ile tam bir küreye dönüşemeyen dağınık bir karar mekânizmasına sahip olduğunu görüyoruz. 50 parametresi ile çalıştırdığımızdaysa, yüzlerce organik gruptan oluşan, muhteşem uyumlu bir heykel niteliğinde bir sonuç ortaya çıkarıyor. Bu sonuç, algoritmanın kendisine verilen birim zaman ile bilişim [data processing] gücüne verdiği en keskin yanıt oldu.
Arşiv Rüyası, 2017
V.K.: Genelde deep dream [derin düş], inceptionism [başlangıçcılık] çok ilginç görüntüler vermiyor. Neden buna başlangıçcılık gibi batınî bir isim verilmiş? Bana geçen hafta Osmanlı Bankası Arşivleri’nden yolladığın iki derin düş görüntüsüyse çok farklı ve yorumlamaya açıktı. Sen bununla ilgilenmeye ne zaman başladın?
R.A.: Google ekibinin 2015 yılı sonunda paylaştığı açık kaynaklı kod sonrasında konuyla ilgilenmeye başladım. Benim için en etkileyici nokta, görsel biçimden öte kavramsal olarak yapay sinir ağlarına insani müdahalenin getirebilecekleriydi. Ocak 2016’da Google’ın Sanatçılar ve Makine Zekâsı ekibinin yeni bir program açtığını ve bu programda makine öğrenmesine ihtiyaç duyulan sanatsal fikirlere sahip kişi ve kurumlara öğretici destek verileceğini öğrendim. Bu kapsamda düzenlenen ilk panelde sanatçı olarak konuşmacı oldum ve orada Google’ın yapay zekâ mühendisleri Mike Tyka ve Kenric McDowell ile SALT projemizi sözlü paylaştım. Ve sonrasında bu alana dair bilgimi pekiştirmeye, yorumunuza katılarak çok ilginç olmayan bu yapay zekâ çıktısı görüntülerini ve onlara dair yöntemleri tekrar yorumlamaya karar verdim. Hâlen medya sanatçısı seviyesinde üretim biçimlerini öğrenmeye devam ediyorum.
Size gönderdiğim ilk denemeler, algoritmanın hata payının en yüksek değerlerine karşılık gelen varsanılarıydı. Bu sırada birkaç yeni fikir daha oluştu: Mike Tyka2 ile arşivin kendi meta veri formatını koruyarak yeni bir halüsinasyon görme biçimi oluşturabilir mi diye düşünmeye başladık. Mesela bu konuşma sırasında bizlere ilham veren şeyin, hem projenin bağlamı hem de bağlamı ortaya çıkaran algoritmaların kendisi olduğunu fark ettik. Tam anlamıyla Google ekibinin ismini verdiği araştırma grubunu haklı çıkarır bir durum; Sanatçılar ve Makine Zekâsı. Algoritmalarla düşünebiliyor olmak ve yapay zekâ ağlarına dair ortaya çıkan eşleştirme sonuçlarına bakıp ilham alabilmek… Bunun, projenin zahmetli fakat bir o kadar da biricik özelliklerinden biri olduğunu düşünüyorum. Acaba bu metotları kullanarak yeni arşiv belgeleri oluşturabilir miyiz? Arşiv, kendi içerisindeki ağların bağlarına dair ilişkileri bir belgeye dönüştürebilir mi? İzleyiciyi çevreleyen, interaktif ve mimari zekâya [architectural intelligence] sahip sergi mekânının en yenilikçi söyleminin, sunacağı halüsinasyonlar olacağını düşünüyorum. Hem alternatif bir gerçeklik hem de kültüre dair bir rüya makinesine doğru giden bir çalışmanın henüz başındayız gibi hissediyorum.
Yapay sinir ağları, bir dizi imgenin iç bağlılıklarını öğrenmek için de kullanılabilir. Bu, imgelerdeki piksellerin birbirlerine göre nasıl davrandıklarının kurallarını, yani imgeleri yöneten kuralları öğrenmek anlamına geliyor. Burada kullandığımız yöntem, iki ağ arasında bir zıtlık oyunu kurmak. Gerçek belgeleri sahte belgelerden ayırmayı öğrenmeye çalışan bir ayırt edici ağ ve ayırt ediciye aykırı görünen sahte içerikler üretmeye çalışan bir üreteç. Üreteç eğitildiği zaman, aynı istatistik kurallarına dayanan yeni görüntüler üretmek için kullanılabililir ve hiç var olmamış ama gerçek belgelere benzeyen belgeler yaratabilir; kim bilir tarihin başka bir sürümünden gelebilecek belgeler gibi…
V.K.: Bu harika bir fikir! Bildiğimiz dünya içinde hiç var olmamış ama gerçek belgelere benzeyen belgeler… Bu, aslında bir başka tarih anlatısı değil, bir paralel dünya; var olanın içine katlanan başka olası dünyalar gibi.
Blaise Agüera y Arcas’ın Sanatçılar ve Makine Zekâsı ile derin düş hakkında yaptığı, benimle de paylaştığın konuşmayı izledim. Tüm mekanizma, percept3‘ten concept‘e çeviri üzerine ve bu çok değerli bir araç. Araştırmalarımızı muazzam derecede kolaylaştırıyor; tanımlama, kataloglama ve ilişkilendirme süreçlerine katkısı olağanüstü. Bir fotoğrafın hangi tarihte çekildiğini anlayabilmek bugün çok daha kolay, içerdiği tüm ögeleri envanterlemek de öyle. Sinir ağına yerleşmesinden ötürü çizgisel sıralamayla da bağları kopuyor.
Bugüne kadar alışmadığımız bir “sanatçı” nosyonu mu söz konusu? Sanatçıların kullandıkları aygıtlarla çok derin ilişkileri olur ama burada aygıtla bir arayüz ilişkisi mi var? Eşiğinde olduğumuz dünya, biricikliğin nesneler üzerinden tarif edilmesine izin vermediği gibi, aygıtın değişken bir zekâsı da mevcut.
R.A.: Çok teşekkürler. Bu projeyi, beraber çıktığımız bir yolculuk olarak algılıyor ve burada daha nice ilham verici ve sürpriz dolu karşılaşmanın olacağına inanıyorum. Kamusal alanda bu denli kompleks, bilişim ve teknoloji odaklı fikir ve tasarılara dair sanat üretimi, kesinlikle alışmadığımız bir “sanatçı” nosyonu oluşturuyor. Size katılarak ve ekleyerek; “sanat” kavramı, makine zekâsıyla kavramsal bir interaktif iletişim kurabildiğimizde yepyeni bir boyut algısı ve dolayısıyla yepyeni bir zaman/mekân kavramı sonucu tamamen değişecektir diye düşünüyorum. Ayrıca, bugüne kadar sanatsal olarak en çok etkilendiğim ışık ve mekân hareketinin -belki de zamanımıza uygun bir şekilde- aygıtla olan ilişkilerimize göre tekrardan can bulabildiğini de görebilmek beni çok heyecanlandırıyor. Mesela, bu projede örtük uzay gibi bir mekânı, tasarladığımız arayüz ile görülebilir kılabiliyor ve oluşumuna tanıklık ediyor olacağız. Bu kendine ait zaman ve mekân kavramı içerisinde, çizgisel olmayan bir zaman ve biricik olmayı ümit eden çok sayıda verinin arasında bir yolculuğa çıkabileceğiz. Bazen bu sohbetimizi bilim-kurgu romanından fırlamış bir kesit gibi düşünüyorum. Biraz zaman geçiyor, bilgisayarımdaki açık pencerelere bakıyor ve aslında gerçek olduğunu görüyorum. İşte bu ve bunun gibi düşünce ve üretim biçimi, yaklaşan devrimin sadece küçük bir izi…
- 1.Algılayıcı, makine öğrenmesinde kullanılan, ikili sınıflandırıcıların terbiye edildiği algoritmadır.
- 2.http://www.miketyka.com/#copper
- 3.Türkçe'de karşılığı olmayan bir kelimedir. Algılama sürecinde geliştirilen zihinsel bir kavram veya bir algı nesnesi olarak düşünülebilir.